Contenu
- Erreur de type I: rejetant à tort l'hypothèse nulle
- Erreur de type II: rejetant à tort le remplaçantHypothèse
- Déterminer leNiveau de signification
- Choisir un test de signification
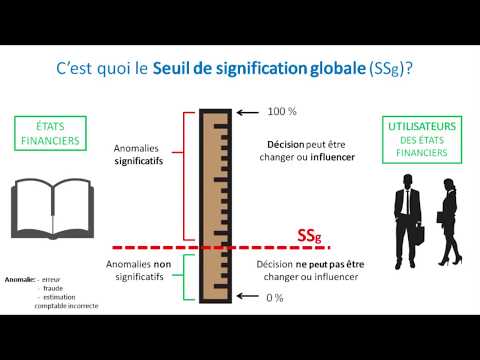
La signification statistique estun indicateur objectif indiquant si les résultats d'une étude sont mathématiquement «réels» et statistiquement défendables, plutôt que simplement un événement fortuit. Couramment utiliséles tests de signification recherchent des différences dans les moyennes des ensembles de données ou des différences dans les variances des ensembles de données. Le type de test appliqué dépend du type de données analysé.Il appartient aux chercheurs de déterminer à quel point ils veulent que les résultats soient significatifs - en d’autres termes, quel risque ils sont disposés à assumer en se trompant. Typiquement,les chercheurs sont disposés à accepter un niveau de risque de 5%.
Erreur de type I: rejetant à tort l'hypothèse nulle
••• Scott Rothstein / iStock / Getty ImagesDes expériences sont menées pour tester des hypothèses spécifiques ou des questions expérimentales avec un résultat attendu. Une hypothèse nulle est celle qui ne détecte aucune différence entre les deux ensembles dedonnées comparées. Dans un essai médical, par exemple, l'hypothèse nulle peut être qu'il n'y a pas de différence d'amélioration entre les patients recevant le médicament à l'étude etpatients recevant le placebo. Si le chercheur rejette à tort cette hypothèse nulle alors qu’elle est en réalité vraie, c’est-à-dire s’ils "détectent" une différence entre les deuxensembles de patients quand il n'y avait vraiment aucune différence, alors ils ont commis une erreur de type I. Les chercheurs déterminent à l'avance quel risque ils commettent une erreur de type Iprêt à accepter. Ce risque est basé sur une valeur p maximale qu'ils accepteront avant de rejeter l'hypothèse nulle, et est appelé alpha.
Erreur de type II: rejetant à tort le remplaçantHypothèse

Une autre hypothèse est celle qui détecte une différence entre les deux ensembles de données comparées. Dans le cas de l'essai médical, vous vous attendriez à voirdifférents niveaux d’amélioration chez les patients recevant le médicament à l’étude et les patients recevant le placebo. Si les chercheurs ne rejettent pas l'hypothèse nulle quand ils le devraient,en d'autres termes, s'ils ne détectent aucune différence entre les deux groupes de patients lorsqu'il y avait réellement une différence, ils commettent alors une erreur de type II.
Déterminer leNiveau de signification
Lorsque les chercheurs effectuent un test de signification statistique et que la valeur p résultante est inférieure au niveau de risque jugé acceptable, le testle résultat est considéré comme statistiquement significatif. Dans ce cas, l'hypothèse nulle - l'hypothèse selon laquelle il n'y a pas de différence entre les deux groupes - est rejetée. En d'autres termes,les résultats indiquent qu'il existe une différence d'amélioration entre les patients recevant le médicament à l'étude et les patients recevant le placebo.
Choisir un test de signification
Il existe plusieurs tests statistiques parmi lesquels choisir. Un test t standard compare les moyennes de deux ensembles de données, telles que les données de notre étude sur les médicaments et nos données du placebo. Un test t apparié estutilisé pour détecter les différences dans le même ensemble de données, tel qu'une étude avant-après. Une analyse de variance unidirectionnelle (ANOVA) permet de comparer les moyennes de trois ensembles de données ou plus,et une ANOVA à deux voies compare les moyennes de deux ensembles de données ou plus en réponse à deux variables indépendantes différentes, telles que les concentrations différentes du médicament à l'étude. Une régression linéairecompare les moyennes des ensembles de données selon un gradient de traitements ou de temps. Chaque test statistique donnera des mesures de signification, ou alpha, pouvant être utilisées pour interpréter le test.résultats.